LLMのEmbeddingモデルで遊んでみたくなったので、これまで書いたメモ同士の類似度計算に使ってみた。
- Markdownの前処理
- LLMでテキスト埋め込み(Embedding)
- 最近傍法(Nearest Neighbor)で類似度を計算
- 可視化
グラフにして可視化したものこちら (新規ウィンドウが開きます)
ごちゃっとまとまっている部分がF1関連。

マネジメント周りのメモもいい感じに感じに関連付けられている。

以下、やったことのメモ
1. Markdownの前処理
基本的にはMarkdownで書いたテキストをそのままモデルに渡せばいいと思うが、記事タイトルやHugoのテンプレート構文をMarkdown形式に寄せた方が良さそう。例えば以下
- Frontmatterに書いているタイトルは
# ...に {{< highlight >}}...{{</ highlight >}}は```...```に{{< relref ... >}}はそのまま文字列に
リンクや画像のメタ情報も含めてもよさそうだけど、今は何もしていない。機械学習あるあるだけど、この前処理の実装が、相対的に時間がかかった部分。
2. LLMでテキスト埋め込み(Embedding)
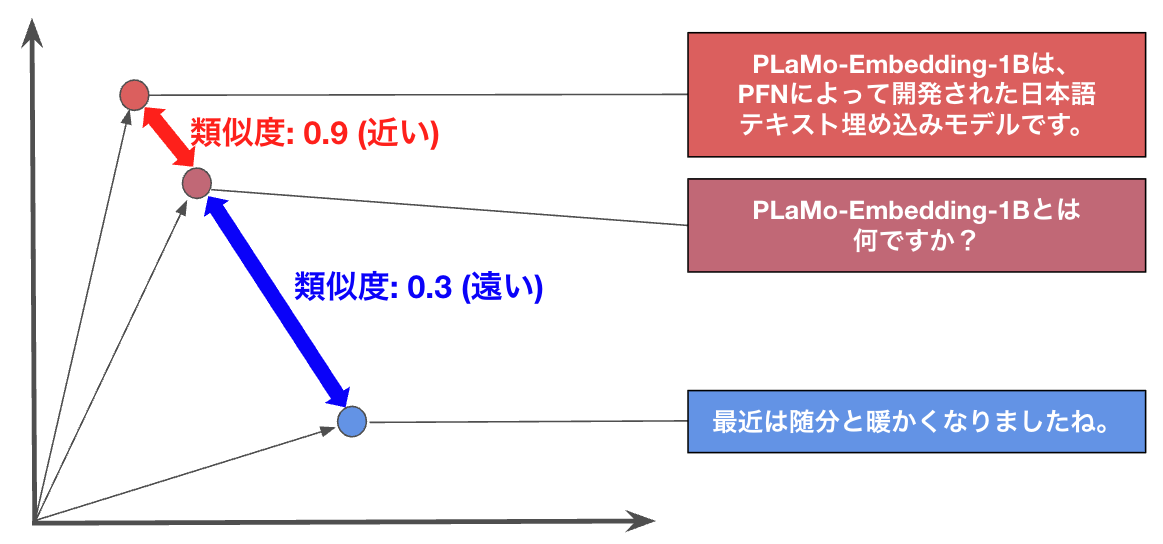
SentenceTransformersを使ってバッチ処理させる。ここがメインの処理だけど、実装自体はとても簡単。
from sentence_transformers import SentenceTransformer
model_name = "pfnet/plamo-embedding-1b"
model = SentenceTransformer(model_name, trust_remote_code=True)
# a list of markdown contents
text_contents = ["markdown contents 1", "markdown contents 2", "markdown contents 3", "..."]
embeddings = model.encode(
text_contents, show_progress_bar=True, batch_size=8, convert_to_numpy=True
)
SentenceTransformers を使わずに自力で平均プーリングを実装するならこんな感じ?
from transformers import AutoModel, AutoTokenizer
model_name = "pfnet/plamo-embedding-1b"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
text = "markdown contents..." # the target markdwon contents
inputs = tokenizer(
text, return_tensors="pt", truncation=True, max_length=512
)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
attention_mask = inputs["attention_mask"].unsqueeze(-1)
masked_embeddings = embeddings * attention_mask
summed = masked_embeddings.sum(dim=1)
counts = attention_mask.sum(dim=1)
mean_pooled = summed / counts
vec = mean_pooled.squeeze().numpy()
3. 最近傍法(Nearest Neighbor)で類似度を計算
教科書通りの最近傍法。
import numpy as np
from sklearn.neighbors import NearestNeighbors
# X is a matrix of embed text, (n, 2048) shape by real
X = [
[0.5914766192436218, 0.767040491104126, 1.7264100313186646],
[3.0219876766204834, 5.411078929901123, 1.0663020610809326],
[-1.4278017282485962, -0.6326829791069031, 2.7116055488586426]
]
# L2 normalization (cosine = dot)
X_norm = X / np.linalg.norm(X, axis=1, keepdims=True)
k = 5
nn = NearestNeighbors(n_neighbors=k + 1, metric="cosine").fit(X_norm)
distances, indices = nn.kneighbors(X_norm, return_distance=True)
# distances = 0..2 (cosine distance); similarity = 1 - distance
sims = 1.0 - distances
たかだか150個弱なので、愚直にペアワイズドで model.similarity 使ってもいい気がする。
4. 可視化
NetworkXでグラフ表現に、PyVizでHTMLに変換した。算出した類似度 sims を線の太さで表現する。
最初Plotlyでちまちまノードとエッジを書いてたけど、ノードをぐりぐり動かすとかできなかったので、 PyVizにした。
まとめ
sims の閾値は色々変えていい塩梅の値にした
良さそうに見えるけど、細かい部分を見ると、つながってほしい部分でつながっていない。ただデバッグが面倒なので、これでいいや、と思っている。

トランプ周りで繋がっていたりいなかったり
一連のコードは以下にアップロードした