エージェントベースでのAIツール開発において、全体のワークフローが多段になるほど、プロンプトだけを使った制御は難しくなり、指示、知識、ツールといったエージェントが扱う情報そのものを管理する必要が出てくる。それら情報をエージェントのコンテキストにどうやって与えるか、その一連の開発をContext Engineeringと呼ぶ。
LangChainのブログがとてもわかりやすかった。

Context Engineeringを以下の4つの分類している
- Writing: 必要な情報をモデルのコンテキストウィンドウの外部に保存し、次の処理ステップで再利用できるようにする。
- Select: 数ある文脈情報の中から、現在のタスクにとって最も関連性の高いものだけをコンテキストウィンドウに取り込む。
- Compress: コンテキストウィンドウ内のトークン数を抑えつつ、必要な意味・情報を損なわずに維持するよう整理・要約する。
- Isolate: 異なるタスク・専門領域・サブエージェント毎に文脈を分割・隔離し、お互いの干渉を防ぎながら効率的に処理を進める。
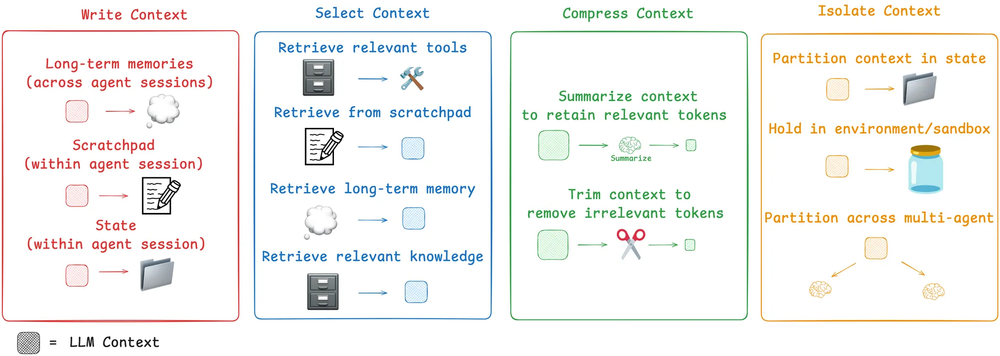
Context Engineeringの一般的な分類(上記ブログより)
文書検索と組み合わせるだけならLlamaIndex、シンプルな処理フローならLangChainで十分。多段なワークフローになりそうであればLangGraphなどのオーケストレーションツール、あるいはDifyのようなプラットフォームツールを検討する。
そうしたフレームワークを使ってAIシステム全体が複雑になる時、上記4つのようなアプローチを理解していると、運用も少しは楽になりそう、と感じる。
上記LangChainのブログで参照されていた、Cognitionのブログも面白かった。
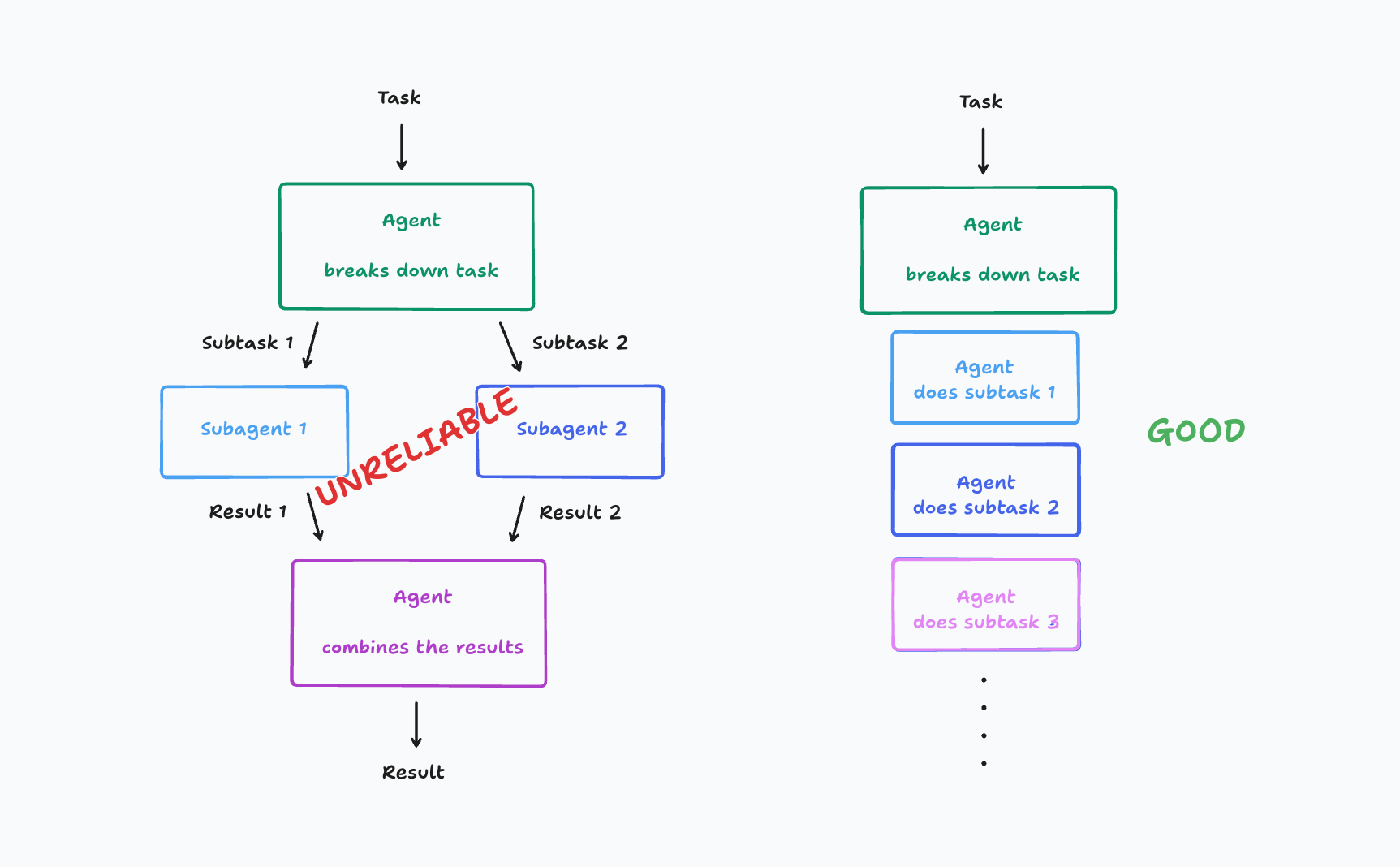
シンプルなAIエージェント利用から、徐々に多段になっていく時、複数のサブエージェント(マルチエージェントアーキテクチャ)で処理を分散させる設計は、コンテキストや状態の共有が困難になり、エラーが蓄積しやすい。この場合は、コンテキストを共有しつつ、エージェントを可能な限りリニアに繋げて処理させるContext Engineeringを推奨している。
ちなみにContext Engineeringという用語は、上記2つのブログの流れののち、ShopifyのCEO Tobias Lütke氏がXで取り上げて、広まったらしい1。
I really like the term “context engineering” over prompt engineering.
— tobi lutke (@tobi) June 19, 2025
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.