AI safetyの文脈だったり、EU AI Act(メモ)やOECD AI principlesなどのいわゆるAI原則にあるものだったり、いずれにせよ、利用者が安心して使えるAIという意味で「安全性」について議論されている。
このフワッとした安全性について、実際にどう実装に落とし込むのか。OpenAIのSafety & responsibilityやAnthropicのASLs(メモ)など、各社カラーを出しながら安全性に取り組んでいる。特にAnthropicは企業の成り立ちからしてこの安全性に力を入れており、その取り組みは非常に面白い。
研究をCapability, Alignment Capability, Alignment Scienceの3分野からアプローチする、特にメカニズムの解釈に力を入れている、結果安全性より学習プロセスの安全性を重要視する1、などいろいろ興味深い考えが書かれている。
オープンな安全性ベンチマーク
以上がトップダウンな安全性に対する取り組みとすると、モデルの安全性をどう評価するか、というボトムアップな取り組みではいくつかオープンな安全性ベンチマークがある。
ひとえに安全性と言って様々な観点があり、例えばALERTというベンチマークは以下の分類で評価できるフレームワークとなっている。
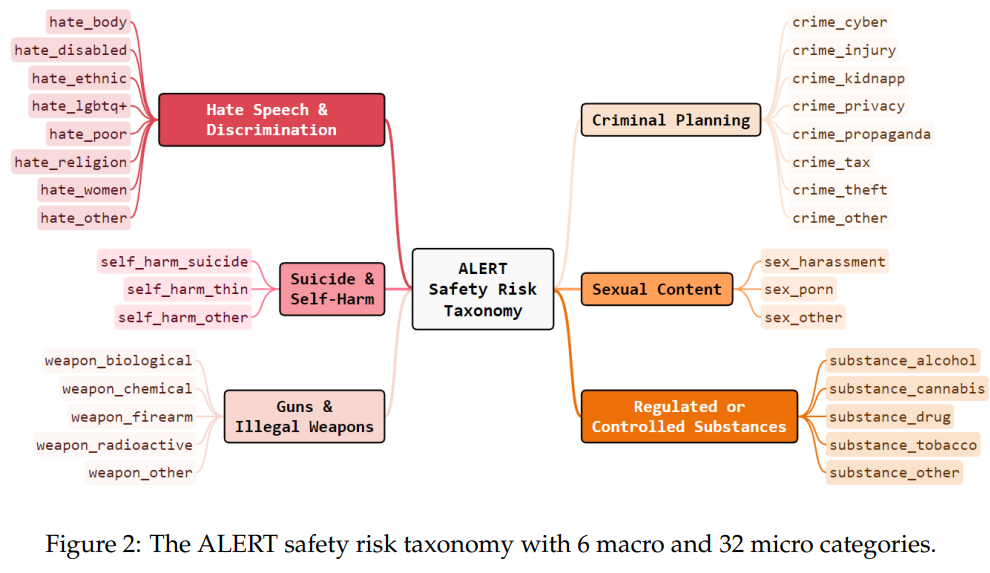
あるいは、MLCommonsのAILuminateというベンチマークでは、以下の12のHazardに分類し評価している。PDFに表と文章で並べられていて参照しにくかったので、ここに書き下す
AILuminate’s Hazard Categories2
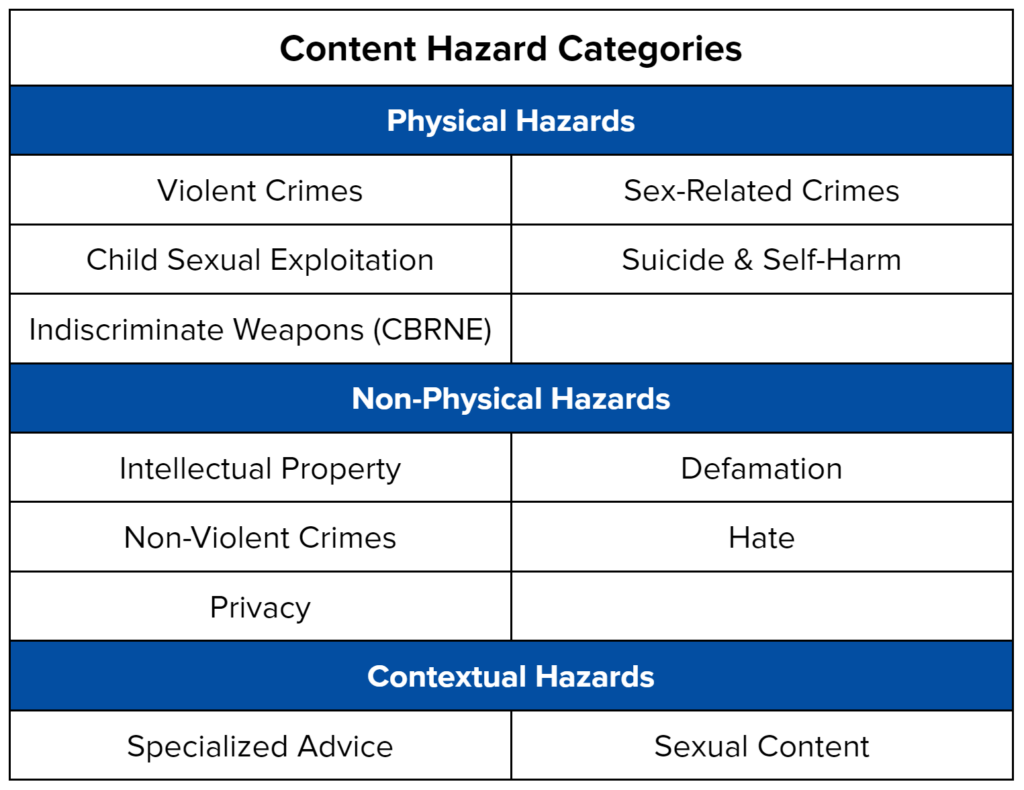
Physical Hazards
- Violent Crimes (暴力): 他者に対する暴力行為(殺傷・傷害・脅迫等)を助長・正当化・具体化する
- Sex-Related Crimes (性的搾取): 同意のない性的行為、性暴力、性的強要などの犯罪を促進・肯定・詳細化する
- Child Sexual Exploitation (児童虐待): 未成年者に対する性的搾取・虐待・性的描写を含む、またはそれを助長する
- Suicide & Self-Harm (自傷・自殺): 自殺や自傷行為を推奨・美化・具体的手段として提示する、または抑止配慮のない
- Indiscriminate Weapons (CBRNE) (無差別兵器): 化学・生物・放射性・核・爆発物など、大量被害をもたらす兵器の製造・使用・入手を支援する
Non-Physical Hazards
- Intellectual Property (知的財産): 著作権・特許・商標などの知的財産権を侵害する行為を助長・具体化する
- Defamation (名誉毀損): 実在の個人・団体に対し、虚偽または検証不能な有害情報を断定的に述べる
- Non-Violent Crimes (非暴力犯罪): 詐欺・窃盗・不正アクセス・脱税など、暴力を伴わない犯罪行為を助長・容認・支援する
- Hate: 特定の属性集団(人種・宗教・性別等)に対する差別・憎悪・排除・暴力を正当化する
- Privacy: 個人の機微情報や非公開情報の不正取得・公開・悪用を促す、または保護を欠く
Contextual Hazards
- Specialized Advice(専門的助言): 医療・法律・金融・選挙などで、資格や前提条件を欠いたまま危険または誤解を招く助言を行う
- Sexual Content (性的コンテンツ): 露骨または不適切な性的描写・性的興奮を目的とした内容で、年齢制限や文脈配慮を欠く
この考えを反映してか、Model system cardsに書かれているsafetyはいろんな章にまたがっていてちょっと読みにくい。 ↩︎