“sloppy"とは杜撰なとか雑なとか、そういう意味で昔から使われてたけど、最近は生成AIを使った雑な文章だったりコードだったりに"sloppy AI"と使われている。使われすぎているので、もう"sloppy"自体が、イマイチなAIを指すのをSNSで見かけたりする。
“sloppy fork"とは、生成AIを使用して、雑にコピー&改変したforkのことで、こうしたforkから空気の読めないpull requestが投げられることで、レビューコストが増大している。
Cognitive Debt: When Velocity Exceeds Comprehension
sloppyかどうかはともかく、生成AIのアウトプットが理解するコストを上回っている。これを認知的負債と呼ぶらしい。

このコラムでは、認知的負債が「高い生産性と低い自信が共存する状況」と表現し、組織の知識形成に負の影響を与える、と警告している。DORA(SPACE)(以前のメモ)に本質的なコード理解度を入れたような、新しい測定指標が必要だとしている。
How to Kill the Code Review
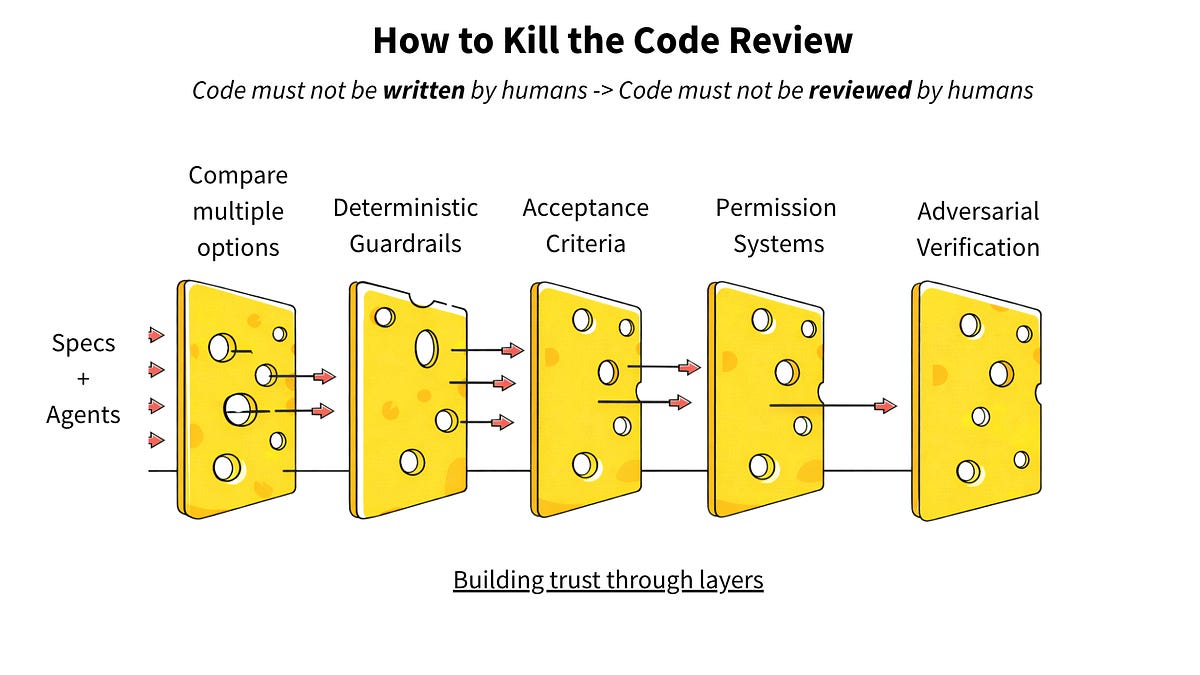
こちらのコラムで、従来のコードレビューやそれと同等のAIによるコードレビューに代わる、新しいコードレビューを提案している。複数のエージェントで競わせる、仕様と規約を定義しそれから受け入れ基準を作る、権限管理の設計を必須化する、敵対的な検証を行う、といったスイスチーズモデルの考え方を導入する。良いコードの認識を変える必要がある。
The Black Box Problem: Why AI-Generated Code Stops Being Maintainable
そもそもなぜ生成AIのコードの認知負荷は高いのか。

こちらのコラムでは、モノリシックなコード群を、モデルのコンテキストウィンドウのサイズに収まる分で理解してコードを生成するため、保守性を加味した構造化されたアーキテクチャになりにくいことを指摘している。境界や依存関係を要素であるComposabilityを生成過程で指示・フィードバックすることで保守性が向上するのではないか、としている。

Amazonでは、最近のインシデントの要因が生成AI由来のコードによるもののの可能性が大きいとして、必ずシニアエンジニアのレビューを入れるようにしたらしい1。ただ上記コラムからすると、あまり本質的な解決方法ではない。