二足歩行ロボットがハーフマラソンを走破するなど1、ますます盛り上がるヒューマノイドロボット界隈。他にも素敵なデモが乱立する中で、実際の実用化までの技術的課題をどう解釈すれば良いか。BCGがこうした誇大広告に対応するための解釈フレームワークを公開していた。

解釈フレームワークに加えて、フィジカルAIの「今」を客観的にさらっていて、そこも良かった。
まずは用語の整理。主にBommasaniらの論文2や、日経新聞の解説3を参考にした。
- 基盤モデル(Foundation Model): 大規模なデータで事前学習され、文章生成・画像認識・検索・推論など幅広い下流タスクへ適応可能な汎用モデルを指す。Bommasani ら2は「広範なデータで学習され、多様な用途へ適応できるモデル」と定義し、GPT や CLIP のようなモデルを代表例として挙げている
- ロボット基盤モデル(Robot Foundation Model): 言語・画像・行動データを横断的に学習し、多様なロボットタスクへ転移可能な汎用ロボットモデルを指す。従来の「特定ロボット専用モデル」と異なり、把持・移動・操作など複数の行動能力を単一モデルへ統合することを目指している
- VLA(Vision-Language-Action Model): 視覚入力と言語指示を受け取り、そのままロボットの行動出力まで生成するモデルを指す。LLM が「テキストの次トークン」を予測するように、VLA は「次に取るべき行動」を予測することで、自然言語から直接ロボット制御を実現する
- フィジカルAI(Physical AI): デジタル空間ではなく物理世界で動作し、環境を認識・行動・操作するAIシステム全般を指す。生成AIやLLMが情報処理中心であるのに対し、フィジカルAIはロボット・自動運転・工場制御のように、現実世界へ直接作用する点が特徴となる
BCG’s Decision Framework
- レベル1:明示的プログラミング
- レベル2:視覚認識
- レベル3:器用な操作能力
- レベル4:ワークフロー計画
- レベル5:推論(Reasoning)能力
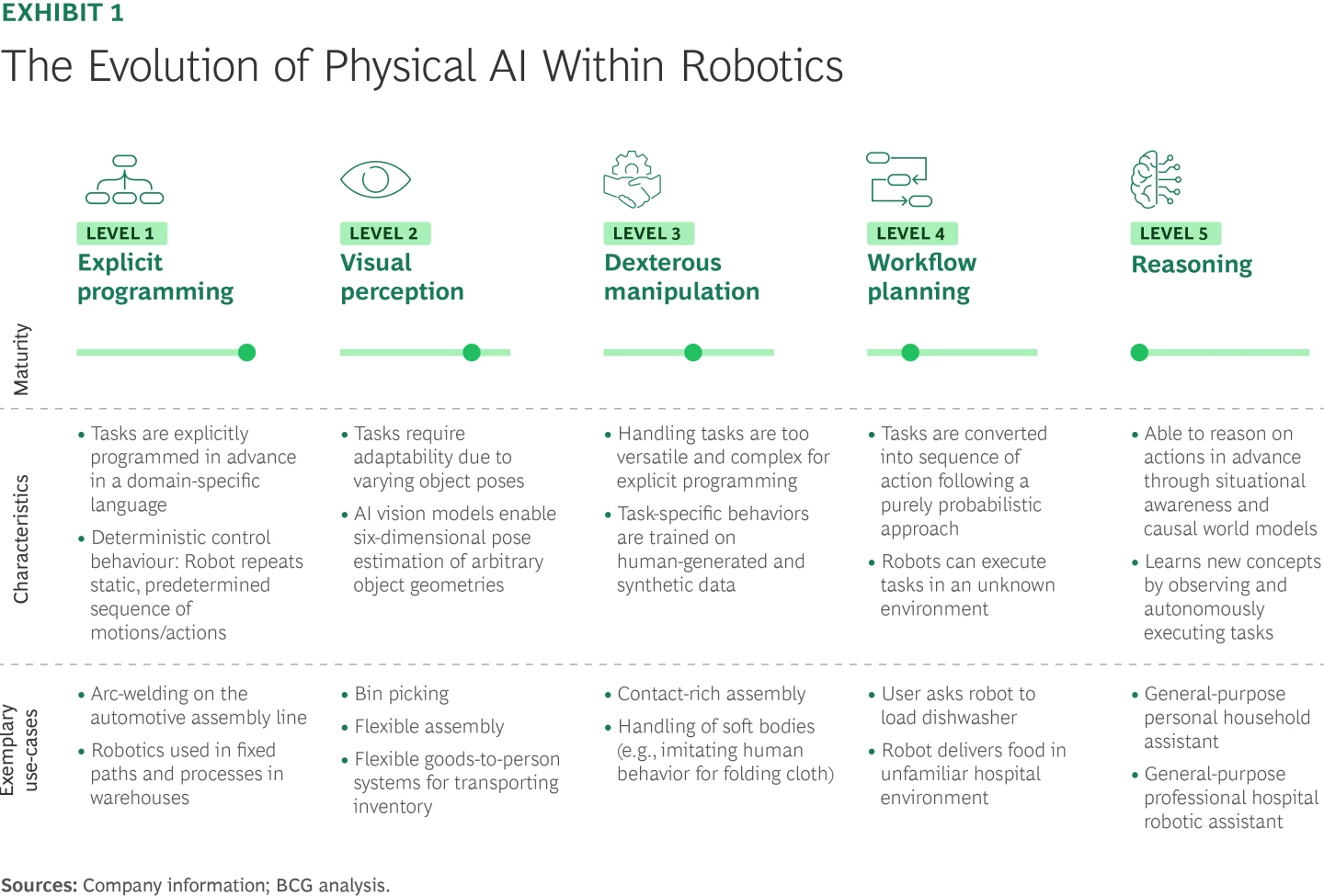
コラム「How Physical AI Is Reshaping Robotics Today」より
レベル2の認識やレベル3の操作は、注目を集めるデモではなく、その技術がもたらす経済性に着目すべきである。VLMの応用により、制約条件はロボットの物体認識能力から、システム構成や検証へと移っている。知覚がモデル化されることで、エンジニアリングワークフローの再構築ができるかがカギ。そしてそれはすでに起こっている。
ロボット導入コストの75%はセットアップとシステム再構築。これらがソフトウェア化することで最大で50%のコスト削減が可能。一方で、レベル3のロボットの操作は、特に柔らかい素材の制御に対して、まだ汎用的な解決に至っていない。ファインチューンされたVLAの初期セットアップコストが低くなるかがカギ。
レベル4のワークフロー計画は、まだ学習したパターンに応じて確率的に行動シーケンスが組まれているだけで、因果関係を推論しているわけではない。この因果的推論能力と段階を踏んだ計画能力が必要である。
レベル5の推論(Reasoning)は、人が暗黙的に行なっている作業を認識し、推論する必要がある。ここはLLMの進歩だけでは不十分であり、ロボット内部に世界モデルが不可欠。それは実現していない。
全体として、技術の成熟度の高いものとコスト効果から、競争優位性を判断すべきである。